柏翠面包机 PE6600 图文教程及其食谱。
食谱和教程应该适用于柏翠面包机系列的机器,其他型号也可以参考本教程。
注意,做面包的原料最好选用专门的面包粉(蛋白质含量大于 13%)和耐高糖酵母。
柏翠面包机 PE6600 图文教程及其食谱。
食谱和教程应该适用于柏翠面包机系列的机器,其他型号也可以参考本教程。
注意,做面包的原料最好选用专门的面包粉(蛋白质含量大于 13%)和耐高糖酵母。
列举日常和网络中所发现的软件、应用、服务等的「作恶」行为,将其永久钉在「耻辱柱」上。有条件的或有候选方案的,应主动弃用之!
坚持开放、坚持自由。点击下载自由软件自由社会.pdf
就事论事,不针对个人、企业、平台,挖掘现象本质,努力尝试寻找更优方案
通常为便于项目开发和调试,开发前期会将多个组件放在同一仓库中,而当各个组件的功能结构和代码逐渐区域稳定后,
便需要将其拆分出来进行独立开发和管理,以便于与其他项目共享组件。
此时,不仅需要将组件所在目录内的代码全部拆分到单独的仓库,同时,还需要确保历史记录能够完整保留。
由于数据库连接十分耗时,采取即需即连的方式会导致应用响应缓慢,因此,在Java应用中均采用数据库连接池统一维护一定数量的Connection对象,连接池中的Connection均保持与数据库的长连接,这样,该连接将随时可用,从而提高应用响应和处理速度。
但是,在普遍的使用不当的情形中,最多的问题便是没有及时释放连接,这里的释放是指将Connection对象归还连接池。若连接未被释放,则连接池将被很快耗尽(Exhausted),从而无法提供新的连接,最终导致应用不能进行数据库操作,并在尝试获取新的连接时出现以下异常:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21...
Caused by: org.hibernate.exception.GenericJDBCException: Could not open connection
at org.hibernate.exception.internal.StandardSQLExceptionConverter.convert(StandardSQLExceptionConverter.java:54)
at org.hibernate.engine.jdbc.spi.SqlExceptionHelper.convert(SqlExceptionHelper.java:125)
at org.hibernate.engine.jdbc.spi.SqlExceptionHelper.convert(SqlExceptionHelper.java:110)
at org.hibernate.engine.jdbc.internal.LogicalConnectionImpl.obtainConnection(LogicalConnectionImpl.java:221)
at org.hibernate.engine.jdbc.internal.LogicalConnectionImpl.getConnection(LogicalConnectionImpl.java:157)
at org.hibernate.internal.SessionImpl.connection(SessionImpl.java:550)
at org.springframework.orm.hibernate4.HibernateTransactionManager.doBegin(HibernateTransactionManager.java:426)
... 9 more
Caused by: org.apache.commons.dbcp.SQLNestedException: Cannot get a connection, pool error Timeout waiting for idle object
at org.apache.commons.dbcp.PoolingDataSource.getConnection(PoolingDataSource.java:114)
at org.apache.commons.dbcp.BasicDataSource.getConnection(BasicDataSource.java:1044)
at org.hibernate.service.jdbc.connections.internal.DatasourceConnectionProviderImpl.getConnection(DatasourceConnectionProviderImpl.java:141)
at org.hibernate.internal.AbstractSessionImpl$NonContextualJdbcConnectionAccess.obtainConnection(AbstractSessionImpl.java:292)
at org.hibernate.engine.jdbc.internal.LogicalConnectionImpl.obtainConnection(LogicalConnectionImpl.java:214)
... 12 more
Caused by: java.util.NoSuchElementException: Timeout waiting for idle object
at org.apache.commons.pool.impl.GenericObjectPool.borrowObject(GenericObjectPool.java:1174)
at org.apache.commons.dbcp.PoolingDataSource.getConnection(PoolingDataSource.java:106)
... 16 more
在开始分析之前先了解一下下面几个相关术语:
有关JVM内存转储方式的说明见JVM内存分析:Tomcat内存泄漏。
最近服务器的内存又在狂飙了,网关响应缓慢,Jenkins完成构建需要长达2个多小时。到底疯狂到什么程度呢?用htop命令看看:
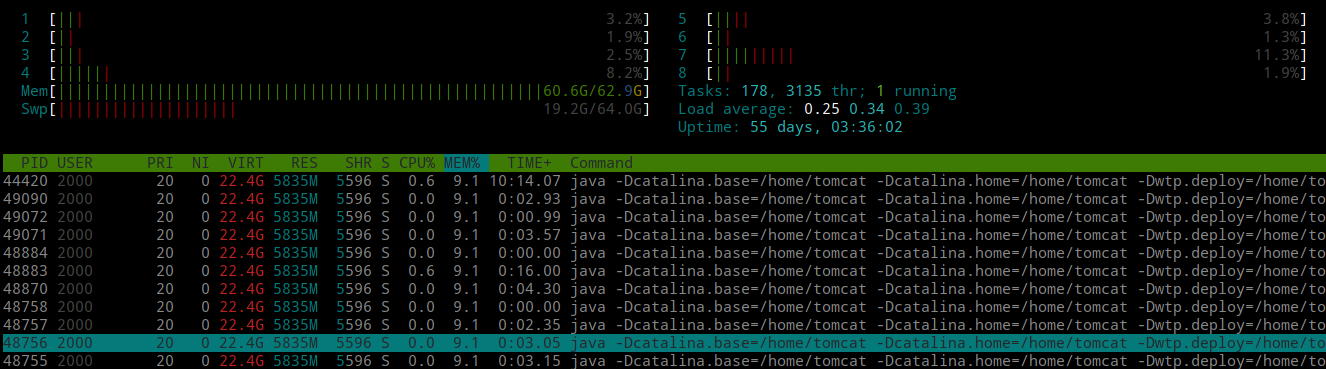
不要仅凭感觉去做性能和代码优化或者是重构代码,一定要以性能测试和监控分析结果为依据,重点优化和改进关键代码和影响常用功能的代码。
需要认识到和牢记的是,局部的小改进对业务整体而言是毫无意义的,只有从全局角度所做的改进才是可感知且有价值的。
不要原地打转:开发工作不要阻塞在单一技术点上,以完成业务功能为首要目标,不影响整体架构的技术难点可利用空闲时间解决
出现任何问题都始终保持就事论事的态度,不要带有个人情绪,不要在未查明根本原因的情况下将问题归咎于个人能力、品行或态度,应优先考虑提升项目管理、工作分配、人员激励、运维管理等制度和服务
线程转储可用于分析Java应用在某一运行时刻的内部线程的运行情况,包括线程数、线程状态(死锁、运行、等待等),并且可得到线程的执行轨迹,对于分析线程死锁十分有益。
通过JDK内置的工具jstack可转储Java线程:sudo -u tomcat jstack -l <java_pid> > jstack.dump,注意,<java_pid>为主进程ID,无法dump某个线程。
获取Java线程ID:
ps aux | grep java;
需确保转储用户与线程用户相同,否则,易出现Unable to open socket file: target process not responding or HotSpot VM not loaded的问题;
当出现死锁时,dump操作可能失败,可以通过kill -3 <java_pid>终止死锁(其不会杀死进程或线程!);
得到转储文件后,可将其上传到fastThread进行在线分析,该服务可提供直观的分析图表和相关报告。
也可以下载IBM提供的工具IBM Thread and Monitor Dump Analyze,其同样提供图表分析功能,但整体上没有fastThread的直观。其启动命令为:java -jar jca447.jar。
通过内存转储可对Java应用内各对象的内存使用情况进行分析,从而找出过度消耗内存或无法及时释放的对象,进而为异常修复以及提升应用加载速度和运行性能提供帮助。
内存转储使用JDK自带的工具jmap(sudo -u tomcat jmap -dump:format=b,file=heap-dump.bin <java_pid>)将应用内存以二进制格式转储到heap-dump.bin中。
需确保转储用户与线程用户相同,否则会出现Unable to open socket file: target process not responding or HotSpot VM not loaded的问题;
转储文件可能会被放到临时目录中,该目录会在Tomcat重启时被删除,所以,一定要在重启前将转储文件转移到安全位置;
转储的文件一般为GB级,可通过命令
xz -k heap-dump.bin进行高强度压缩,得到压缩文件heap-dump.bin.xz。解压使用命令unxz -k heap-dump.bin.xz,其中,-k选项均表示保留原文件,否则原文件将会被删除;
The post isn’t finished yet, it will be updated anytime!
提要:
算法分析系列文章中的代码可被任何人无偿使用于任何场景且无需注明来源也不必在使用前征得本文作者同意。
算法分析系列文章旨在传播准确、完整、简洁、易懂、规范的代码实现,并传授基本的编程思想和良好的编码习惯与技巧。
若文章中的代码存在问题或逻辑错误,请通过邮件等形式(见文章结尾)告知于本文作者以便及时修正错误或改进代码。
算法系列文章不可避免地会参考和学习众多网友的成果,在行文风格、内容及求解思路上也会进行借鉴,如有侵权嫌疑,请联系本文作者。
PS:若为转载该文章,请务必注明来源,本站点欢迎大家转载。
如果序列 中的所有元素按照其在 中的出现顺序依次出现在另一个序列 中,则称 为 的子序列。
子序列不要求位置的连续性(即,元素相邻),只要相对顺序不变即可。
若给定一个序列集合(数量大于或等于2,但通常为两个序列),则这些序列所共同拥有的子序列,称为公共子序列。而在这些公共子序列中长度最长的子序列则称为该序列集合的最长公共子序列(Longest Common Sequence, LCS)。
本例所要求的便是求解任意两个序列的最长公共子序列(可能存在多个不同的序列),并打印其长度及其其中的任意一个序列。