提要
在开始分析之前先了解一下下面几个相关术语:
- Shallow Heap:对象自身占用的内存大小(包含基本数据类型),不包括它引用对象的大小;
- Retained Heap:Shallow Heap + 所有直接或者间接引用对象占用的内存(即该对象被GC回收后,可以被回收的内存);
- GC Root:被堆外对象引用的对象;
- Dominator Tree:以支配树方式描述的对象引用关系;
有关JVM内存转储方式的说明见JVM内存分析:Tomcat内存泄漏。
案例分析
最近服务器的内存又在狂飙了,网关响应缓慢,Jenkins完成构建需要长达2个多小时。到底疯狂到什么程度呢?用htop命令看看:
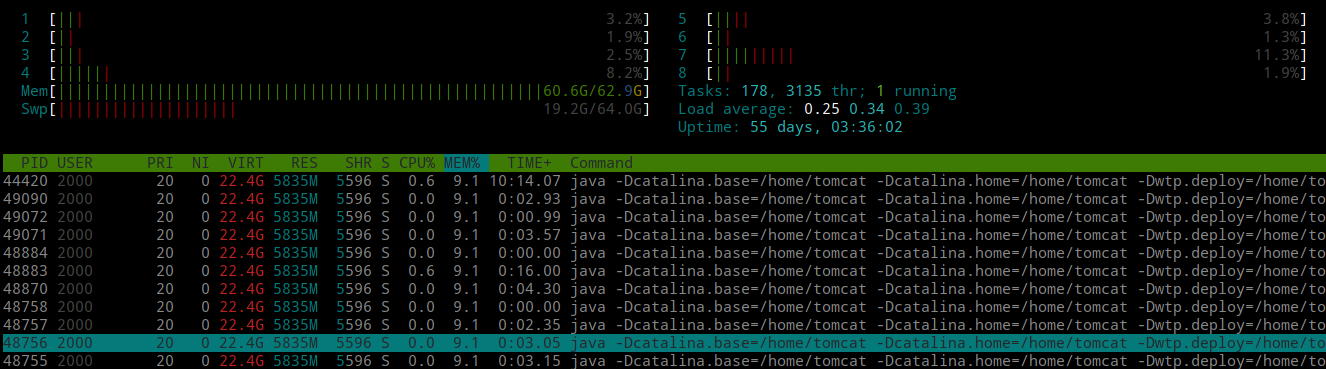
不仅64G内存几乎耗尽,还占用了大量的交换分区空间(也就是虚拟内存),实在异常恐怖!
再查看哪些进程耗用内存较多,结果发现都是Docker容器内的应用进程消耗最多。那使用命令docker stats --format "table {{.Name}}\t{{.Container}}\t{{.CPUPerc}}\t{{.MemUsage}}\t{{.NetIO}}\t{{.BlockIO}}"看看各个容器的内存使用情况:
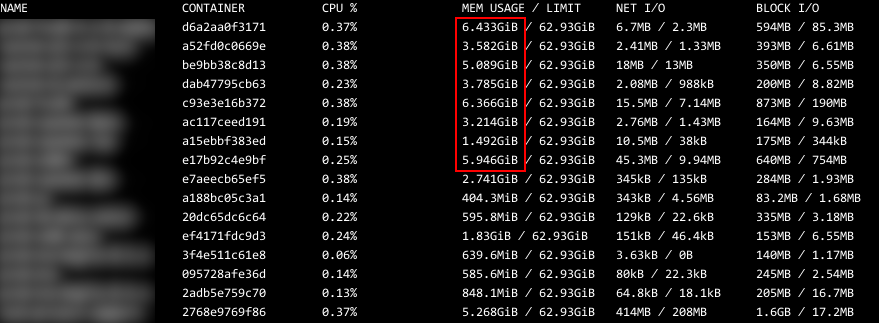
从使用情况来看,有多个应用容器的内存使用量在5GB以上,而且部分应用实际上并没有什么耗内存的地方,却也占用了5GB,实在是不可理喻。
没有办法了,只能dump出应用的堆内存,再详细分析内存都消耗在哪些对象上了。
在容器内运行命令sudo -u tomcat jmap -dump:format=b,file=heap-dump.bin <java_pid>将Tomcat进程的堆内存转储至heap-dump.bin中。
转储完成后,通过Eclipse Memory Analyzer - MAT自带的工具ParseHeapDump.sh分析堆内存(也同时分析其中的unreachable对象以得到对象内部数据):ParseHeapDump.sh -keep_unreachable_objects heap-dump.bin。
最后,启动MAT并点击菜单File -> Open Heap Dump选择文件heap-dump.bin,得到如下结果:
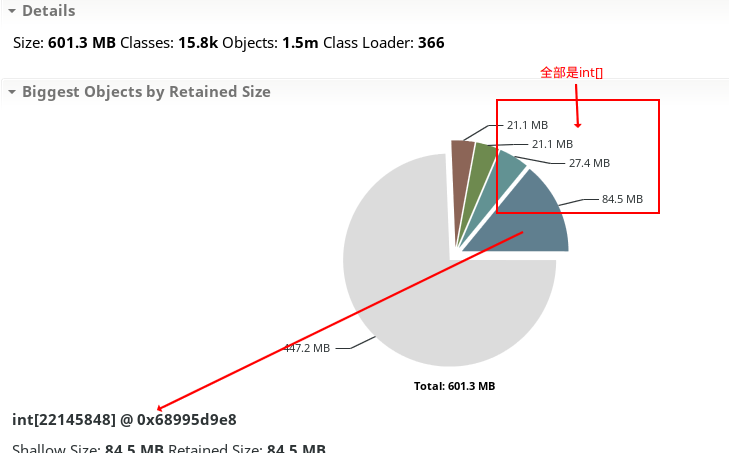
结果很出乎意料:int[]数组居然占用了数十兆内存,总计占了1/4!
接着看看直方图(Histogram),注意需将结果按Shallow Heap降序排序:
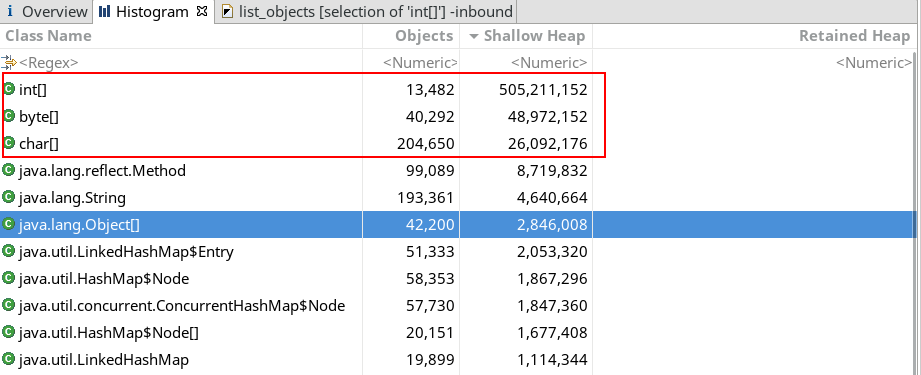
这更是惊人:int[]数据总共为505,211,152字节,也就是481MB!
惊讶继续!
右键点击int[]并选择List objects -> with incoming references(PS:同样按Shallow Heap降序排序):
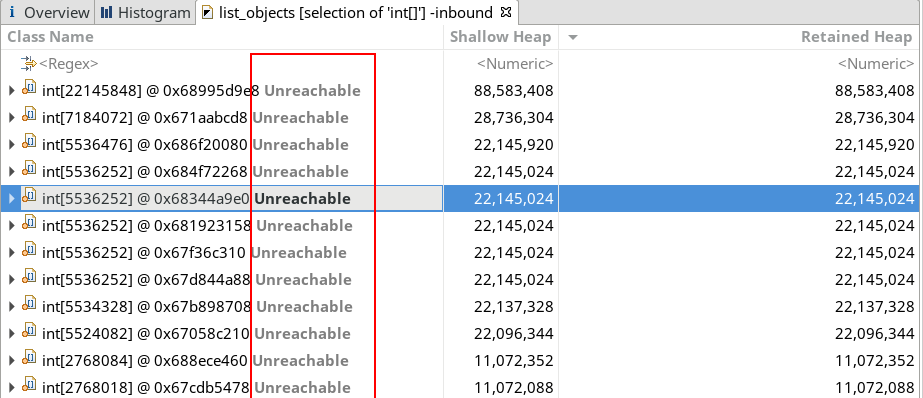
从incoming references中可以发现以下问题:
- 几乎所有的
int[]都是unreachable的; - 靠前的
int[]长度都达到数十万,甚至百万、千万;
那么,问题来了:
- 谁创建了这么多且这么大的数组,又为何创建?
- 数组里存的是什么数据,干什么用的?
第一个问题没有可解答的线索,因为查不到引用这些数组的对象。不过从第二个问题中应该能找寻到一些蛛丝马迹。
在incoming references中右键点击第一条并选择Copy -> Save Value To File,将数组内的数据保存到文件int-bytes.bin中。
因为得到的文件为二进制的,故需使用工具hexedit查看其内容(PS:也可用其他二进制查看工具)。
打开文件后向下翻页直至右侧出现有大量连续可识别的字符为止:

截取其中的一段内容:
1 | 002CEEA8 00 00 00 00 00 00 00 00 00 00 00 01 00 00 00 00 F8 00 00 ED 00 00 00 3A 41 54 45 4D 46 4E 49 2D 72 65 73 2F 65 63 69 76 .......................:ATEMFNI-res/eciv |
这里会发现一个问题:这些字符看起来很有规律,感觉很熟悉但却又很陌生。
不过仔细辨别还是可以发现:每四个相邻字符反序再组合也就能够还原出正确的字符串。比如,截图中便可识别出一串字符:META-INF/services/javax.xml.parsers.DocumentBuilderFactory。
为什么转存的二进制文件会出现字符串反序呢?其实,这便是著名的大小端字节序。而该文件正好为小端字节序(低位字节在前,高位字节在后),和人类的读写顺序(大端字节序)正好相反。
有点「反人类」了。
为了确保能正常识别int[]中存储的内容,我们需要将小端字节序转换为大端字节序。
不幸的是,没能找到直接可用的大小端转换工具,于是拿起遗忘已久的C语言编写以下一段代码来进行转换:
1 |
|
使用GCC编译(gcc -o swap-endian main.c)并运行swap-endian以转换大小端:./swap-endian ./int-bytes.bin ./int-bytes.bin.swap。
然后,再用hexedit打开int-bytes.bin.swap并按组合键Ctrl+G跳转到刚才查看的位置。这下字符顺序终于正常了:

反序问题解决了,接下来就来擦亮眼睛去发现int[]中都有些什么吧。
最后从该数组中发现其包含了以下一些字符串:
jar:file:/xxx/xxx/xxx.jarMETA-INF/services/xxx.xxx.XxxXX/usr/lib/jvm/java-8-openjdk-amd64/jre/lib/xerces.propertiescom/sun/org/apache/xpath/internal/jaxp/XPathFactoryImpl.classorg/activiti/db/mapping/entity/Task.xml(及其内容)、org.activiti.engine.impl.TablePageMap.classjar:file:/xxx/xxx/WEB-INF/lib/xercesImpl-2.6.2.jar!/META-INF/services/javax.xml.parsers.DocumentBuilderFactory
有什么发现没?反正我是感觉这可能是ClassLoader的内容或者与此相关的某些东西。而且这些也不是业务对象数据,基本都是*.class、*.java以及jar中的资源文件的名称和内容,那这就和应用本身没啥关系了,问题出在JVM层面的可能性更大。
如果是这样,那为何会出现这样的问题呢?
我也是茫然无知,多番假设和验证后也没有结果,最后,只得Google了一下关键字java big int array unreachable,并从Java String objects not getting garbage collected on time中找到了些线索:
This means the VM will eat memory until it hits the maximum and then, it will do one huge GC run:即,Java GC的开销很大(evil),因此其会尽可能多地使用内存直到超过最大限定值,非万不得已不会主动GCUnless you see OutOfMemoryException, you don't have a leak:即,如果没有抛出OutOfMemoryException异常,那么就不会是内存泄漏,那怕是内存被全部耗尽However when we inspect these char[], Strings we find that they do not have GC roots which means that they shouldn't be the cause of leak. Since they are a part of heap, it means they are waiting to get garbage collected:即,Unreachable对象不会引发内存泄漏,其属于堆内数据,正等待被垃圾回收
联系实际情况:在Docker镜像构建配置中,Tomcat的启动脚本并未设置JVM的堆大小,而且从长时间的观察来看,容器的内存消耗会随时间逐步增长,并且在多次数据查询后内存使用也是会直线增长。再结合以上线索,便可初步确定这是JVM没有GC造成的。
按照以上思路,为Tomcat启动脚本设置JVM堆内存的最大值和初始值,再重启并运行一段时候后发现容器的内存使用情况趋于正常,静默下的内存消耗降至百兆,有数据查询时内存使用会上升到1GB左右,并在没有数据查询时出现回落:
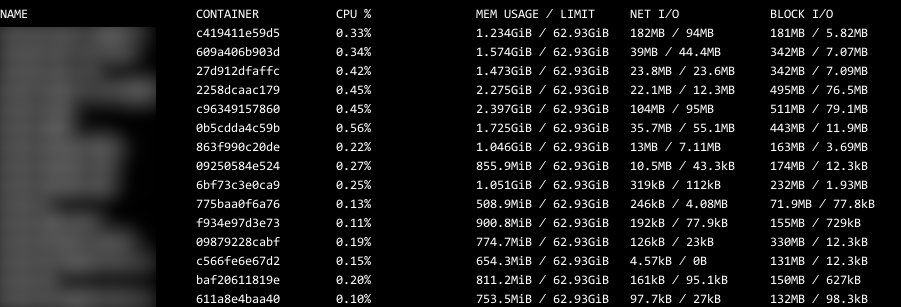
内存使用也回归正常:
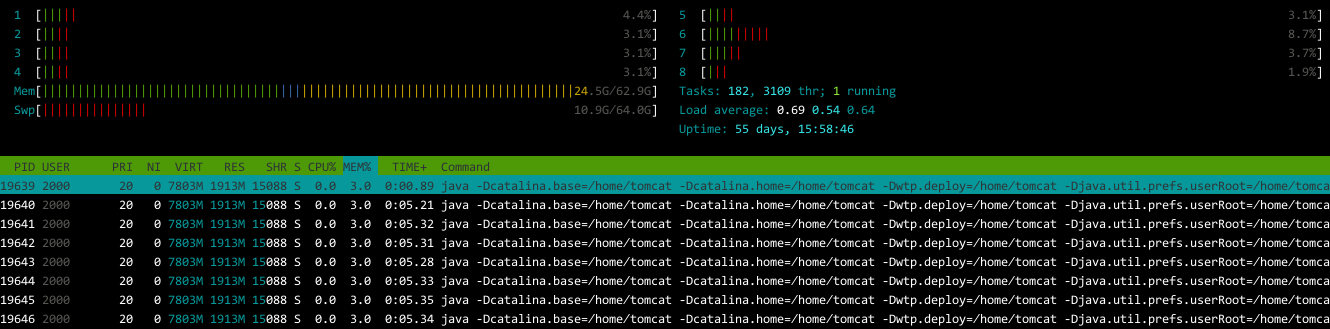
看来问题还真就是出在JVM的GC机制上,悬了长久的问题终于得到解决。
这里不禁要感叹:
原来你是这样的Java!!
解决方案
对症下药,调整Docker镜像的entrypoint脚本为如下内容(PS:非全部内容,需根据实际情况调整):
1 | # 在JDK8以前的版本中需将“-XX:MetaspaceSize=512m -XX:MaxMetaspaceSize=512m”改为“-XX:PermSize=512m -XX:MaxPermSize=512m” |
对Tomcat调整Java参数,需新增或编辑文件
${TOMCAT_HOME}/bin/setenv.sh,并按这里的内容调整环境变量JAVA_OPTS的值。
在以上脚本中还指定了出现OOM时的堆转储文件以及GC日志的存储位置。
获取到GC日志后可以通过在线工具GCeasy分析JVM的GC情况。注意:在生产环境中也应该设置OOM时的堆转储文件以便于分析内存溢出问题。
注意,以上内容并不一定是最佳设置,需根据实际情况进行调整,如果存在以下情况,可尝试适当增加-Xms(初始堆内存)和-Xmx(最大堆内存)的值:
- 应用需要加载大量的Class;
- 应用运行期间需要创建大量对象或在数组中存放大量数据;
- 从GC日志中发现进行GC的频率较高、间隔较短;
通过GCeasy也可以得到很好的改进建议;
堆内存分配过大会导致一次GC的耗时增加,而GC操作会挂起应用,因此,不可盲目设置过大值;
GC日志行的格式说明如下(Understanding Garbage Collection Logs):

参考
- Eclipse Memory Analyzer - MAT
- Java String objects not getting garbage collected on time
- What are the Xms and Xmx parameters when starting JVMs?
- 排查Java的内存问题
- Java中堆内存和栈内存详解
- How to Enable Garbage Collection (GC) Logging
- Understanding Garbage Collection Logs:解释
GC (Allocation Failure)行的格式 - JVM调优经验
- JVM参数优化(基础篇)
附录
${TOMCAT_HOME}/bin/setenv.sh
1 |
|

